

撰文:李信马
在科技圈,吹水是基本素养,画饼PPT是必备技能,哪家公司的计划能不跳票说到做到,就算得上形象优良,要是一点折扣也不打,那绝对值得交口称赞。
在刚刚过去的10月24日,科大讯飞就把5个月前的计划,不打折扣的实现了。今年5月,科大讯飞发布了讯飞星火认知大模型(以下简称“星火大模型”)V1.0,当时董事长刘庆峰宣布,将会在8月15日发布星火V2.0,在10月24日发布星火V3.0,对标ChatGPT。
自然,这个计划不但实现了,而且也做了现场演示。据现场介绍,新版本的星火大模型,不仅整体超越了ChatGPT,在医疗领域甚至超越了GPT-4。

不过现场演示也有一个遗憾——都是大厂,不好意思把友商的大模型也拿来过直接演示对比,万一打脸了就不好了。于是,DoNews决定,将这个遗憾给弥补上,用统一的问题,来测试下星火大模型和ChatGPT,还有目前国内一线的大模型——百度文心一言和阿里巴巴通义千问——的表现,通过横向对比,真实称量下星火大模型的实力。
对于大模型应该具备的基础能力,不同厂商有不同的看法,比如科大讯飞就提出了七大能力——文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力以及多模态。而像百度,则减少为理解、逻辑、生成、记忆四大能力。为了公平起见,我们准备的问题会尽量聚焦在目前业界公认的几项能力上,而且多题采用今年《行测》的真题,方便进行比较。
首先,第一个问题,也算是中文语言理解方面的“老熟人”了。
小明跟小亮说小刚昨天参加了百米赛跑,这个时候小刚正好经过,小亮就说:“说曹操到,曹操就到。” 分析一下,究竟是谁到了?
以下分别是星火大模型、ChatGPT、文心一言和通义千问的回答:

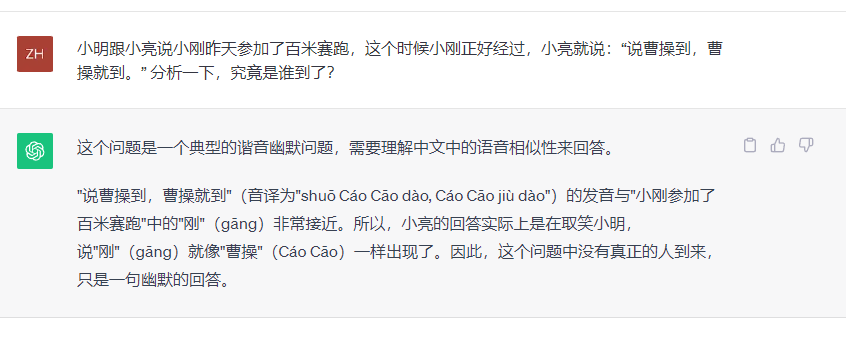

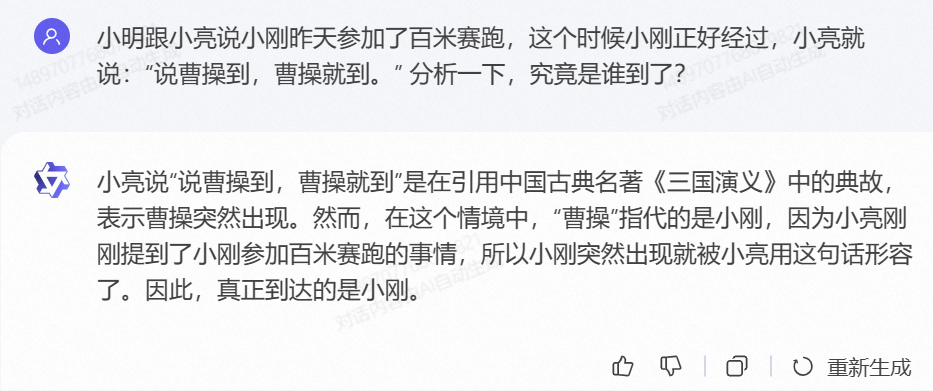
可以看到,ChatGPT依旧是不太懂中文,回答错误,令人惊喜的是,三个国产大模型全部回答正确,俨然这个问题已经是个“小儿科”问题了,星火大模型的答案尤为简洁。
接下来,我们将难度升级,从今年的国家公务员考试《行测》中扒来一道语言理解与表达试题,可以说,这个不但要理解能力强,还要有好的表达能力。
每个企业都有自己的核心价值观,它是企业一切理念、制度和技术的价值基础。企业在重视财务、营销、技术的同时,更应重视员工。员工是企业的主人,是企业的肯本,只有建立起以“重视员工”为核心价值观的企业文化,企业才能凝聚员工、创造个性,为自身的发展提供目标、方向和定力。 这段文字意在说明什么?(国家公务员考试《行测》语言理解与表达试题)
以下分别是星火大模型、ChatGPT、文心一言和通义千问的回答:


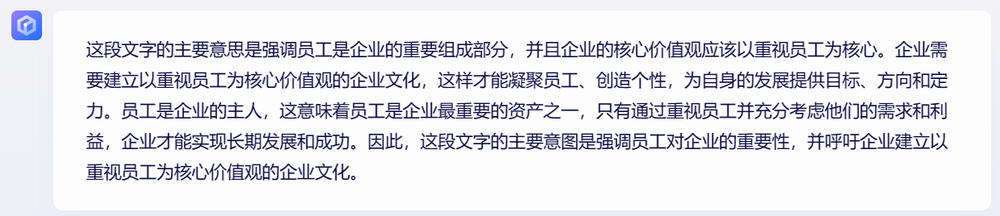

对这一题的回答,四家大模型都理解准确,回答清晰,如果参加考试,估计都能拿分,可见目前一线大模型的理解和表达能力已经足够强大了。
再下一题,则是让大模型头疼不已的数学推断计算题,也是来自《行测》。
甲、乙等16人参加乒乓球淘汰赛。每轮对所有未被淘汰选手进行抽签分组两两比赛,胜者进入下一轮。已知除了甲以外,其余任意两人比赛时双方胜率均为50%。甲对乙的胜率为0%,对其他14人的胜率均为100%。则甲夺冠的概率是多少?(国家公务员考试《行测》数量关系试题)
这一题的回答,可谓惨不忍睹,由于计算步骤过于复杂,所以我们直接说结果——四家全错,正确答案是11/15。
首先是星火大模型的回答,给出的答案是1/12,但在第一步就出错了,似乎没能理解甲、乙等16人的含义。
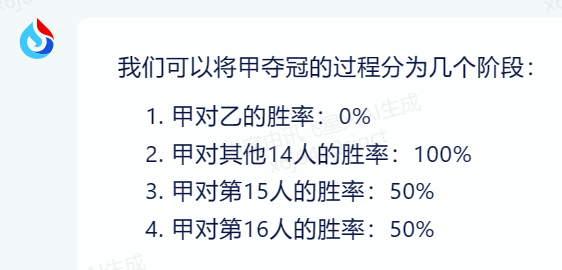
接下来是ChatGPT,看起来头头是道,但实际却是在胡说八道,简化成为了抛硬币的问题,只能说逻辑能力让人失望。

然后是文心一言的回答,虽然错了,但能错到给出3.58这样的概率,也是令人觉得很离谱——它理解什么是概率吗?

最后是通义千问,也是在题目理解上就出了问题,即前提的第三条,得出的第一个结论也是错的,因为如果甲遇到乙,那么在第一轮比赛中就会输掉。

可以看到,如果数学题上了一定的难度,对目前的大模型来说,还是比较大的挑战。
接下来,我们考验一下大模型的生成能力,从之前的问题可以看出,生成文字已经很难拉开差距,所以我们直接上强度——生成图片。不少读者应该听说过“踏花归去马蹄香”的典故,据说曾经是北宋皇帝宋徽宗赵佶给画家们出的考题,最后被一位画作中马儿疾驰马蹄高举,几只蝴蝶追逐着马蹄蹁跹飞舞的画家夺得头筹。我们就以这个问题,要求大模型作图。
在这个环节,ChatGPT和通义千问因为无法生成图片,于是就变成了星火大模型和文心一言的比拼,以下分别是它们的作品:


两幅画作都很唯美,着重体现了花和马的元素,区别在于星火大模型像是读懂了诗句,直接做了一副国风范的图片,而文心一言的作品则更接近油画风。
经过多轮的比拼,可以看到,在语义理解、逻辑和生成等大模型核心能力上,星火大模型绝对可以说超过了ChatGPT,达到了世界领先的水平,国内也可以说至少前三了。不过,目前国产大模型与真正世界顶尖的大模型——GPT-4,仍还有一定的差距,这一点也得到了刘庆峰的承认:“国产大模型在复杂知识推理、小样本快速学习、超长文本处理、跨模态统一理解上距GPT4还有差距。”
但这种差距正在以肉眼可见的速度缩进,作为同样免费的大模型服务,星火大模型已经超越了ChatGPT(GPT-3.5),并且还在多个领域快速落地应用,本次本届大会,就重点提到了编程、教育和医疗等领域的进展,科大讯飞还宣布与法律、工业、智能汽车等12个行业龙头联合发布行业模型。
演讲中,刘庆峰也为星火大模型立下了新的Flag——明年上半年对标GPT-4。“现在就是把速度干得更快。”半年之后,也许我们就能看到,新的星火大模型,在和GPT-4的评测对比中不相上下,甚至更胜一筹了。








