
DoNews7月25日消息,AI 创业公司 MosaicML 近日发布了其 70 亿参数模型 MPT-7B-8K,据悉,该模型一次可以处理 8000 字文本,相当擅长处理长文重点摘要和问答,还能在 MosaicML 平台上根据特定任务,进一步微调相关配置。
据悉,系列模型采用了 150 万个 Token,并以 256 块 H100 GPU 花 3 天完成模型训练而成。MosaicML 本次发布了 3 个版本模型,包括 MPT-7B-8k、MPT-7B-8k-Instruct 和 MPT-7B-8k-Chat。
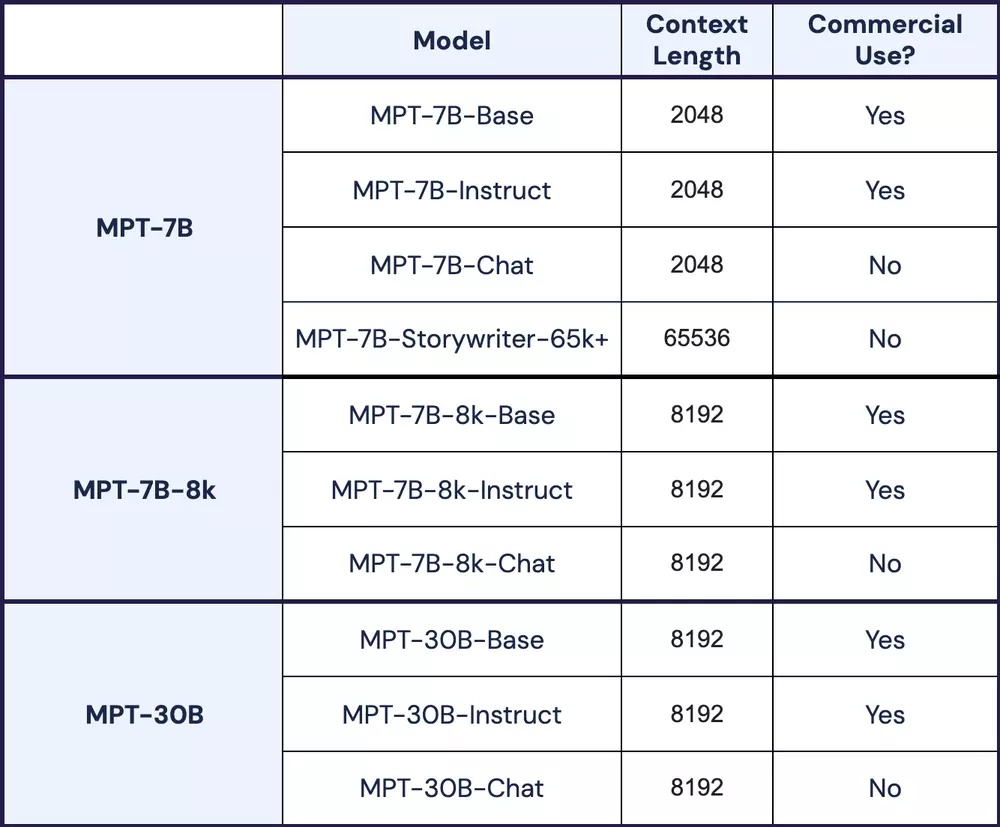
其中,第一个版本 MPT-7B-8k、是以 Transformer 解码器为基础,并以 FlashAttention 和 FasterTransformer 机制来加速训练与推论,能一次处理 8000 字文本,MosaicML 公司表示,该模型开源、允许商用。
第二个版本 MPT-7B-8k-Instruct 是以第一个版本 MPT-7B-8k 微调而成,MosaicML 公司表示,MPT-7B-8k-Instruct 模型可处理长篇指令,特别注重于生成“摘要和问答”,该模型一样开源且可商用。
第三个版本 MPT-7B-8k-Chat 则是机器人对话式的 AI 模型,MosaicML 公司宣称,该模型额外多用了 15 亿个聊天数据 Token,在第一版模型 MPT-7B-8k 之上继续训练而成,该模型开源,但不允许商用。








