

撰文 | 田小梦
编辑 | 杨博丞
题图 | NVIDIA
3月22日,在刚刚结束的GTC 大会上,NVIDIA创始人兼首席执行官黄仁勋围绕AI、芯片、云服务等前沿科技,带来一系列“杀手级”技术和产品。
从OpenAI发布GPT-4,到百度发布文心一言,再到微软将GPT-4接入自己全套办公软件Microsoft 365 Copilot,乃至昨日谷歌正式宣布开放 Bard 的访问权限。在这AI的决定性时刻,黄仁勋也是激动地三次强调,“我们正处于AI的iPhone时刻”。
“如果把加速计算比作曲速引擎,那么AI就是动力来源。生成式 AI 的非凡能力,使得公司产生了紧迫感,他们需要重新构思产品和商业模式。”黄仁勋说道。
手握算力技术的英伟达自然是不会缺席AI产品。自今年年初ChatGPT爆火后,吸引了超过1亿用户,成为有史以来增长最快的应用。英伟达的股价也是一路飙升,目前英伟达市值为6471亿美元。
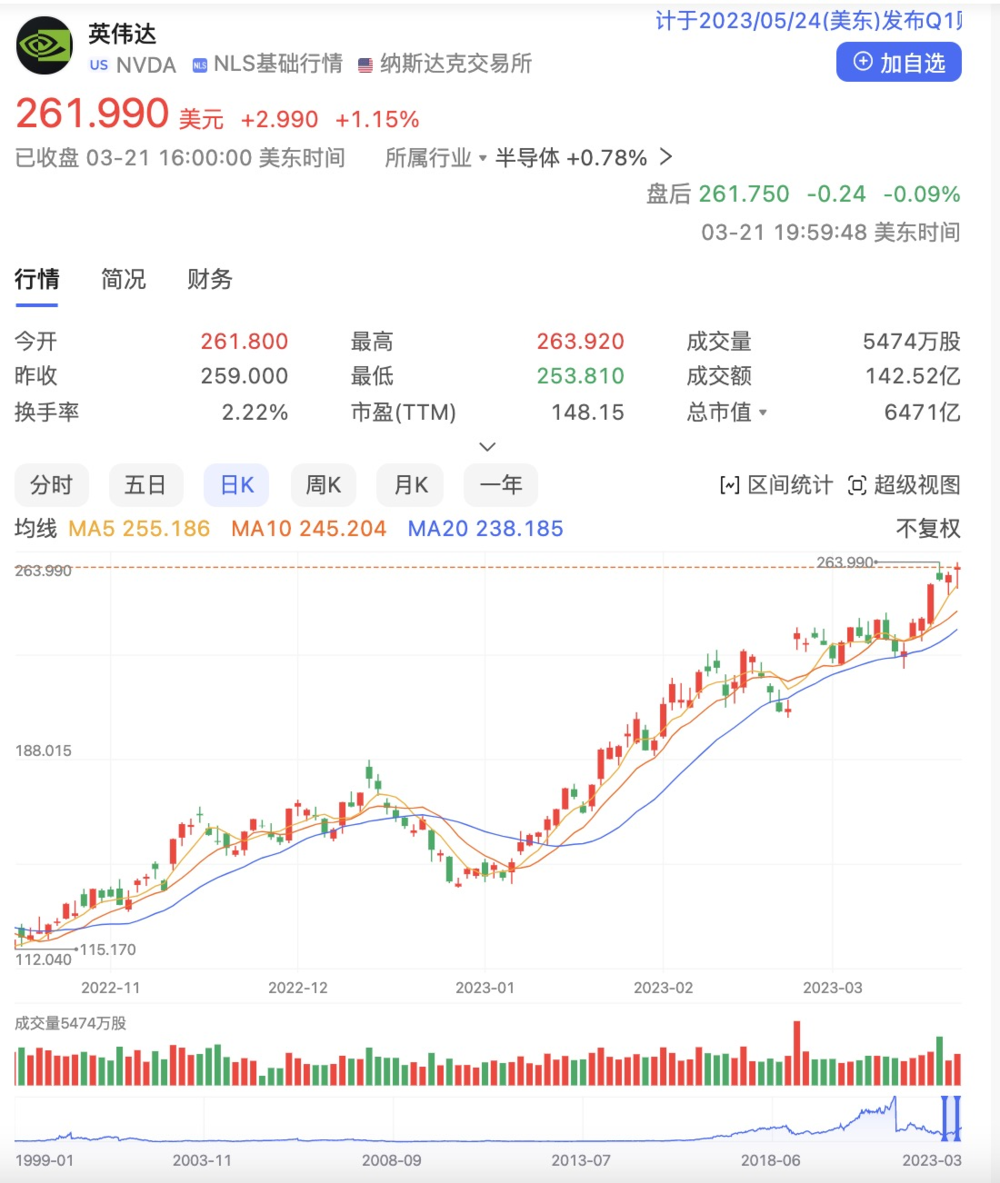
图片来源:百度股市通
一、做AI界的“台积电”
自十年前AlexNet面市以来,深度学习就开辟了巨大的新市场,包括自动驾驶、机器人、智能音箱,并重塑了购物、了解新闻和享受音乐的方式。随着生成式AI掀起的新一波浪潮,使得推理工作负载呈阶梯函数式增长。
对此,今日英伟达推出全新的推理平台:四种配置—一个体系架构—一个软件栈,其中,每种配置都针对某一类工作负载进行了优化。

首先,ChatGPT等大型语言模型是一个全新的推理工作负载,GPT模型是内存和计算密集型模型。同时,推理是一种高容量、外扩型工作负载,需要标准的商业服务器。为了支持像ChatGPT这样的大型语言模型推理,黄仁勋发布了一款新的GPU——带有双GPU NVLink的H100 NVL,配备94GB HBM3显存,可处理拥有1750亿参数的GPT-3,还可支持商业PCIE服务器轻松扩展。
黄仁勋表示,目前在云上唯一可以实际处理ChatGPT的GPU是HGX A100,与适用于GPT-3处理的HGX A100相比,一台搭载四对H100及双GPU NVLINK的标准服务器的速度快10倍。“H100可以将大型语言模型的处理成本降低一个数量级。”
其次,针对AI视频工作负载推出了L4,对视频解码和编码、视频内容审核、视频通话功能等方面进行了优化如今,大多数云端视频都在CPU上处理,一台8-GPU L4服务器将取代一百多台用于处理AI视频的双插槽CPU服务器。Snap是NVIDIA AI 在计算机视觉和推荐系统领域领先的用户,Snap将会把L4用于AV1视频处理生成式AI和增强现实。
再者,针对Omniverse、图形渲染等生成式AI,推出L40,L40的性能是NVIDIA最受欢迎的云推理GPU T4的10倍。Runway是生成式AI领域的先驱,他们正在发明用于创作和编辑内容的生成式AI模型。
此外,为用于推荐系统的AI数据库和大型语言模型,推出了Grace Hopper超级芯片。通过900GB/s高速芯片对芯片的接口,NVIDIA Grace Hopper超级芯片可连接Grace CPU和Hopper GPU。“客户希望构建规模大几个数量级的AI数据库,那么Grace Hopper是最理想的引擎。”
与此同时,面对生成式AI的认知将重塑几乎所有行业的现状。黄仁勋坦言称:“这个行业需要一个类似台积电的代工厂,来构建自定义的大型语言模型。”
为了加速企业使用生成式AI的工作,黄仁勋发布了NVIDIA AI Foundations云服务系列,为需要构建、完善和运行自定义大型语言模型及生成式AI的客户提供服务,他们通常使用专有数据进行训练并完成特定领域的任务。
NVIDIA AI Foundations包括NVIDIA NeMo是用于构建自定义语言文本-文本转换生成模型;Picasso视觉语言模型制作服务,适用于想要构建使用授权或专有内容训练而成的自定义模型的客户,以及BioNeMo,助力2万亿美元规模的药物研发行业的研究人员,帮助研究人员使用他们的专有数据创建、微调和提供自定义模型。
二、加深云服务体系
“云”也是此次发布会的重点之一,推出了NVIDIA DGX Cloud。
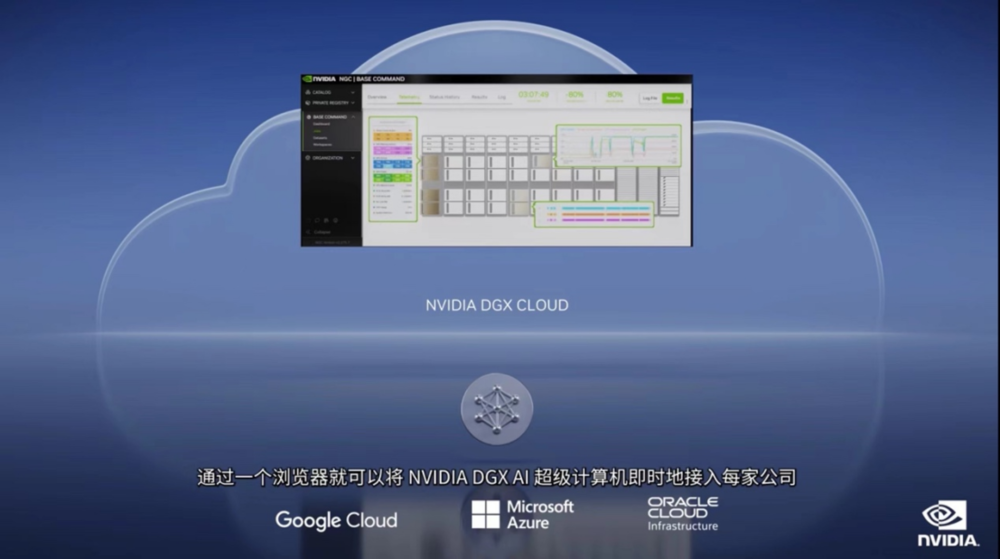
这项AI超级计算服务使企业能够即时接入用于训练生成式AI等开创性应用的高级模型所需的基础设施和软件。DGX Cloud可提供NVIDIA DGX AI超级计算专用集群,并配以NVIDIA AI软件。
这项服务可以让每个企业都通过一个简单的网络浏览器就能访问自己的AI超级计算机,免除了购置、部署和管理本地基础设施的复杂性。
黄仁勋表示:“初创企业正在竞相打造颠覆性的产品和商业模式,老牌企业则在寻求应对之法。DGX Cloud 使客户能够在全球规模的云上即时接入NVIDIA AI超级计算。”
目前,NVIDIA正与领先的云服务提供商一起托管DGX Cloud基础设施,Oracle Cloud Infrastructure(OCI)首当其冲,通过其OCI超级集群,提供专门构建的RDMA网络、裸金属计算以及高性能本地块存储,可扩展到超过32000个GPU所组成的超级集群。微软Azure预计将在下个季度开始托管DGX Cloud,该服务将很快扩展到Google Cloud等。
黄仁勋表示,此次合作将NVIDIA的生态系统带给云服务提供商,同时扩大了NVIDIA的规模和影响力。企业将能够按月租用DGX Cloud集群以便快速、轻松地扩展大型多节点训练工作负载的开发。
随着云计算发展,在过去十年中,大约3000万台CPU服务器完成大部分处理工作,但挑战即将到来。随着摩尔定律的终结,CPU性能的提高也会伴随着功耗的增加。另外,减少碳排放从根本上与增加数据中心的需求相悖,云计算的发展受功耗限制。
黄仁勋指出,加速云数据中心的CPU侧重点与过去有着根本性的不同。过去数据中心加速各种工作负载,将会减少功耗,节省的能源可以促进新的增长,未经过加速的工作负载都将会在CPU上处理。在AI和云服务中,加速计算卸载可并行的工作负载,而CPU可处理其他工作负载,比如Web RPC和数据库查询。为了在云数据中心规模下实现高能效,英伟达推出Grace。
Grace包含72个Arm核心,由超高速片内可扩展的、缓存一致的网络连接,可提供3.2TB/s的截面带宽,Grace Superchip通过900GB/s的低功耗芯片到芯片缓存一致接口,连接两个CPU芯片之间的144个核,内存系统由LPDDR低功耗内存构成(与手机上使用的相似),还专门对此进行了增强,以便在数据中心中使用。

通过Google基准测试(测试云微服务的通信速度)和Hi-Bench套件(测试Apache Spark内存密集型数据处理),对Grace进行了测试,此类工作负载是云数据中心的基础。
在微服务方面,Grace的速度比最新一代x86 CPU的平均速度快1.3倍;在数据处理中,Grace则快1.2倍,而达到如此高性能,整机功耗仅为原来服务器的60%。云服务提供商可以为功率受限的数据中心配备超过1.7倍的Grace服务器,每台服务器的吞吐量提高25%。在功耗相同的情况下,Grace使云服务提供商获得了两倍的增长机会。

“Grace的性能和能效非常适合云计算应用和科学计算应用。”黄仁勋说道。
三、为2纳米光刻技术奠基
随着对芯片制造的精确度提升,当前生产工艺接近物理学的极限。光刻即在晶圆上创建图案的过程,是芯片制造过程中的起始阶段,包括光掩模制作和图案投影。
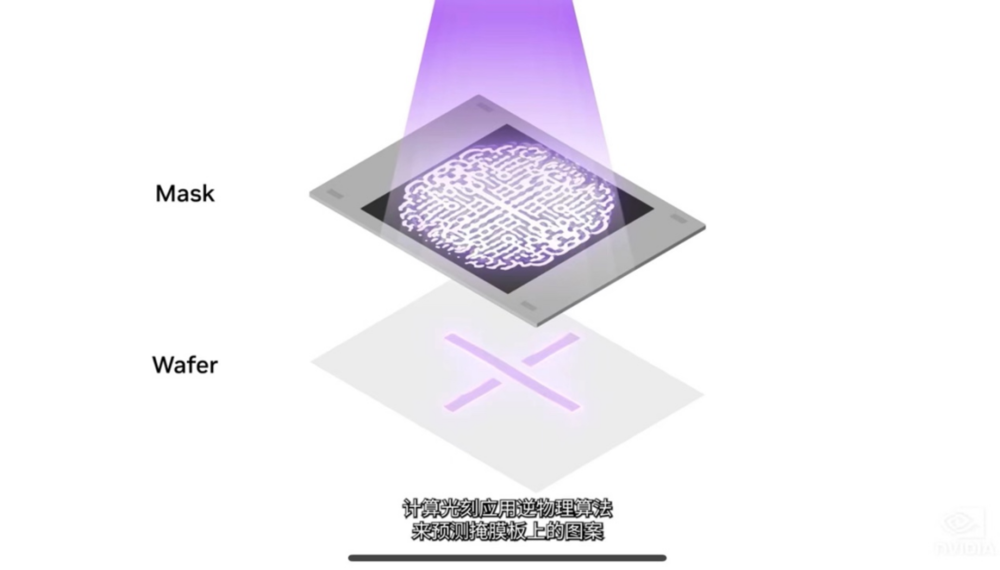
其中,计算光刻是芯片设计和制造领域中最大的计算工作负载,每年消耗数百亿CPU小时,大型数据中心24 x7全天候运行,以便创建用于光刻系统的掩模版。数据中心是芯片制造商每年投资近2000亿美元的资本支出的一部分,随着算法越来越复杂,计算光刻技术也在快速发展,使整个行业能够达到2纳米及以上。
对此,在本次发布会上,黄仁勋带来了一个计算光刻库——NVIDIA cuLitho。

“芯片产业几乎是每一个行业的基础。”黄仁勋介绍称,cuLitho是一项历时近四年的庞大任务,英伟达与台积电、ASML和Synopsys等密切合作,将计算光刻加速了40倍以上。
NVIDIA H100需要89块掩模版,在CPU上运行时,处理单个掩模版当前需要两周时间。如果在GPU上运行cuLitho,只需8小时即可处理完一个掩模版。
据介绍,台积电可以通过在500个DGX H100系统上使用cuLitho加速,将功率从35MW降至5MW,从而替代用于计算光刻的4万台CPU服务器。借助cuLitho,台积电可以缩短原型周期时间、提高产量、减少制造过程中的碳足迹,并为2纳米及以上的生产做好准备。
此外,台积电将于6月开始对cuLitho进行生产资格认证,ASML正在GPU和cuLitho方面与NVIDIA展开合作,并计划在其所有计算光刻软件产品中加入对GPU的支持。
不难看出,从AI训练到部署,从系统到云服务,再到半导体芯片,黄仁勋打出了一套“组合拳”。站在AI的风口,黄仁勋也透露出“胜券在握”的信心。








